An Introduction to Evaluation Metrics for Object Detection
Introduction
The purpose of this post was to summarize some common metrics for object detection adopted by various popular competitions. This post mainly focuses on the definitions of the metrics; I’ll write another post to discuss the interpretations and intuitions.
Popular competitions and metrics
The following competitions and metrics are included by this post1:
1 The ImageNet Object Detection Challenge (Russakovsky et al. 2015) also has an evaluation metric for object detection. However, it is not as common as the others so it is not included here.
- The PASCAL VOC Challenge (Everingham et al. 2010)
- The COCO Object Detection Challenge (Lin et al. 2014)
- The Open Images Challenge (Kuznetsova 2018).
The links above points to the websites that describe the evaluation metrics. In brief:
- All three challenges use mean average precision as a principal metric to evaluate object detectors; however, there are some variations in definitions and implementations.
- The COCO Object Detection challenge2 also includes mean average recall as a detection metric.
2 According to some notes from the COCO challenge’s metric definition, the term “average precision” actually refers to “mean average precision”. Similarly, “average recall” should perhaps be re-termed as “mean average recall”. This post makes distinctions among these terms.
Some concepts
Before diving into the competition metrics, let’s first review some foundational concepts.
Confidence score is the probability that an anchor box contains an object. It is usually predicted by a classifier.
Intersection over Union (IoU) is defined as the area of the intersection divided by the area of the union of a predicted bounding box (\(B_p\)) and a ground-truth box (\(B_{gt}\)):
\[ IoU = \frac{area(B_p \cap B_{gt})}{area(B_p \cup B_{gt})} \quad (1) \]
Both confidence score and IoU are used as the criteria that determine whether a detection is a true positive or a false positive. The pseudocode below shows how:
for each detection that has a confidence score > threshold:
among the ground-truths, choose one that belongs to the same class and has the highest IoU with the detection
if no ground-truth can be chosen or IoU < threshold (e.g., 0.5):
the detection is a false positive
else:
the detection is a true positiveAs the pseudocode indicates, a detection is considered a true positive (TP) only if it satisties three conditions: confidence score > threshold; the predicted class matches the class of a ground truth; the predicted bounding box has an IoU greater than a threshold (e.g., 0.5) with the ground-truth. Violation of either of the latter two conditions makes a false positive (FP). It is worth mentioning that the PASCAL VOC Challenge includes some additional rules to define true/false positives. In case multiple predictions correspond to the same ground-truth, only the one with the highest confidence score counts as a true positive, while the remainings are considered false positives.
When the confidence score of a detection that is supposed to detect a ground-truth is lower than the threshold, the detection counts as a false negative (FN). You may wonder how the number of false positives are counted so as to calculate the following metrics. However, as will be shown, we don’t really need to count it to get the result.
When the confidence score of a detection that is not supposed to detect anything is lower than the threshold, the detection counts as a true negative (TN). However, in object detection we usually don’t care about these kind of detections.
Precision is defined as the number of true positives divided by the sum of true positives and false positives:
\[ precision = \frac{TP}{TP + FP} \quad (2) \]
Recall is defined as the number of true positives divided by the sum of true positives and false negatives (note that the sum is just the number of ground-truths, so there’s no need to count the number of false negatives):
\[ recall = \frac{TP}{TP + FN} \quad (3) \]
By setting the threshold for confidence score at different levels, we get different pairs of precision and recall. With recall on the x-axis and precision on the y-axis, we can draw a precision-recall curve, which indicates the association between the two metrics. Figure 1 shows a simulated plot.
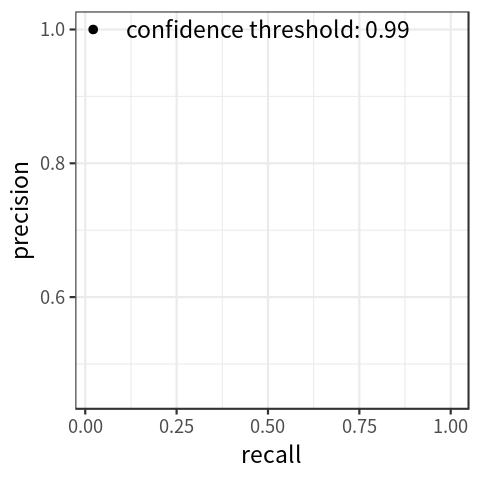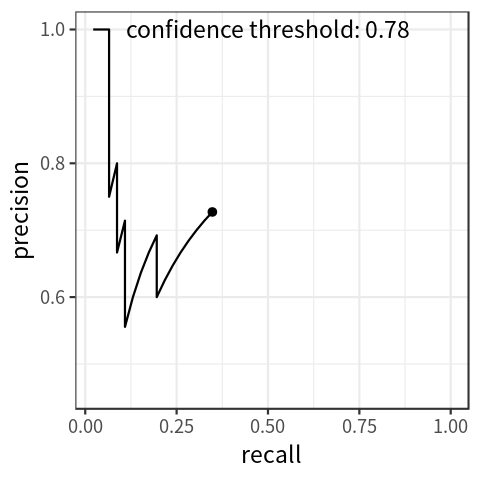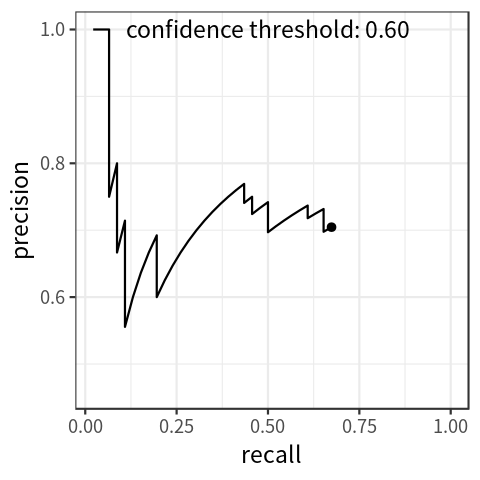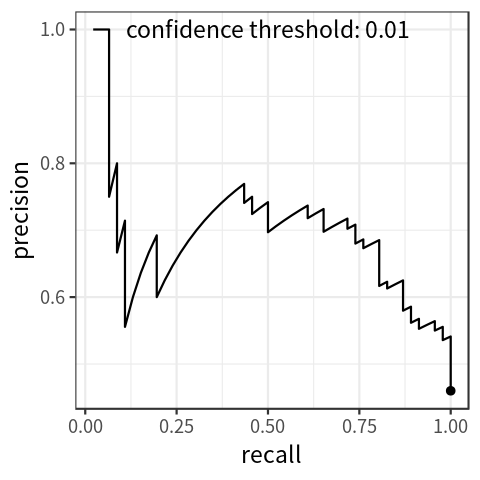
Note that as the threshold for confidence score decreases, recall increases monotonically; precision can go up and down, but the general tendency is to decrease.
In addition to precision-recall curve, there is another kind of curve called recall-IoU curve. Traditionally, this curve is used to evaluate the effectiveness of detection proposals (Hosang et al. 2016), but it is also the foundation of a metric called average recall, which will be introduced in the next section.
By setting the threshold for IoU at different levels, the detector would achieve different recall levels accordingly. With these values, we can draw the recall-IoU curve by mapping \(IoU \in [0.5, 1.0]\) on the x-axis and recall on the y-axis ( Figure 2 shows a simulated plot).
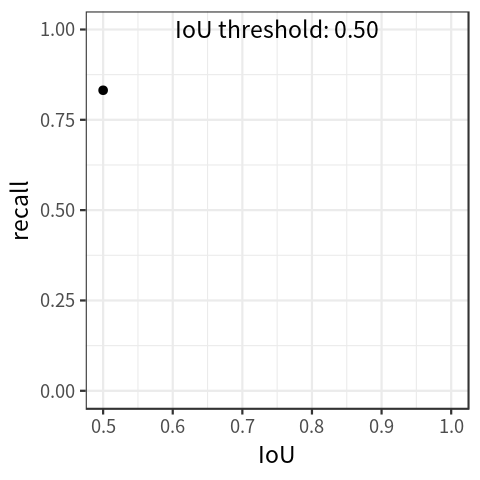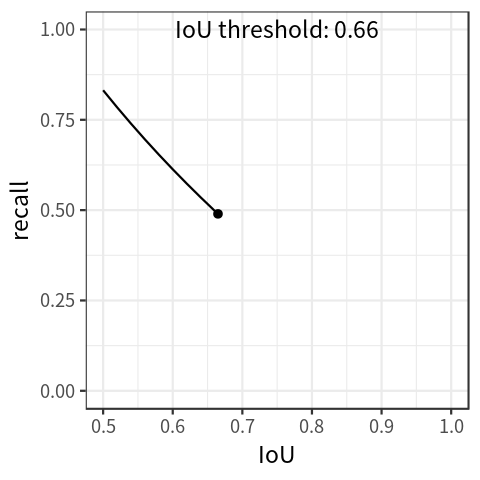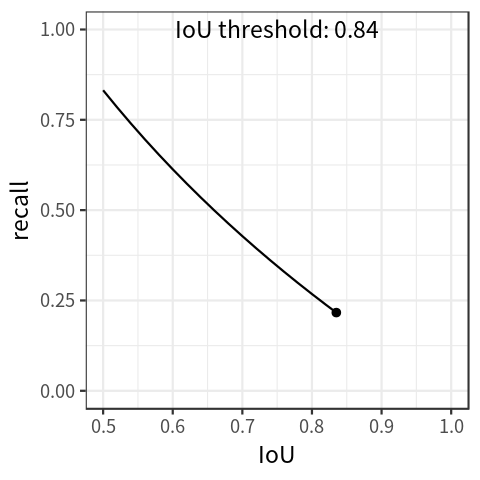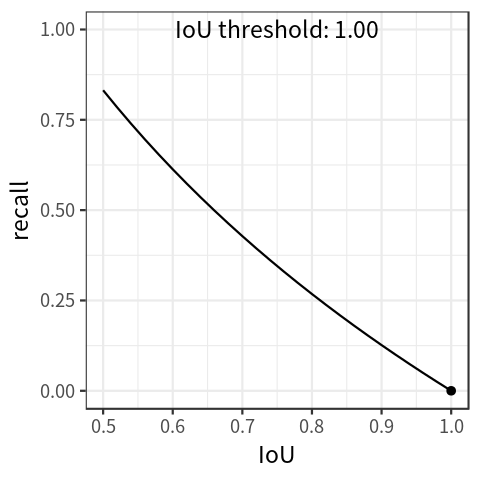
The curve shows that recall decreases as IoU increases.
Definitions of various metrics
This section introduces the following metrics: average precision (AP), mean average precision (mAP), average recall (AR) and mean average recall (mAR).
Average precision
Although the precision-recall curve can be used to evaluate the performance of a detector, it is not easy to compare among different detectors when the curves intersect with each other. It would be better if we have a numerical metric that can be used directly for the comparison. This is where average precision (AP), which is based on the precision-recall curve, comes into play. In essence, AP is the precision averaged across all unique recall levels.
Note that in order to reduce the impact of the wiggles in the curve, we first interpolate the precision at multiple recall levels before actually calculating AP. The interpolated precision \(p_{interp}\) at a certain recall level \(r\) is defined as the highest precision found for any recall level \(r' \geq r\):
\[ p_{interp}(r) = \max_{r' \geq r} p(r') \quad (4) \]
Note that there are two ways to choose the levels of recall (denoted as \(r\) above) at which the precision should be interpolated. The traditional way is to choose 11 equally spaced recall levels (i.e., 0.0, 0.1, 0.2, … 1.0); while a new standard adopted by the PASCAL VOC challenge chooses all unique recall levels presented by the data. The new standard is said to be more capable of improving precision and measuring differences between methods with low AP. Figure 3 shows how the interpolated precision-recall curve is obtained over the original curve, using the new standard.
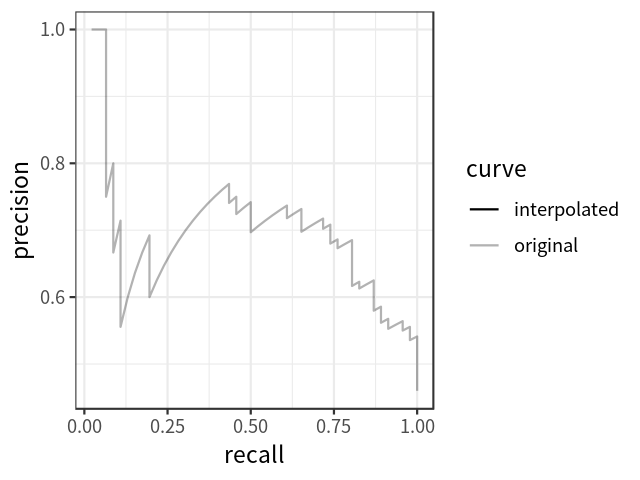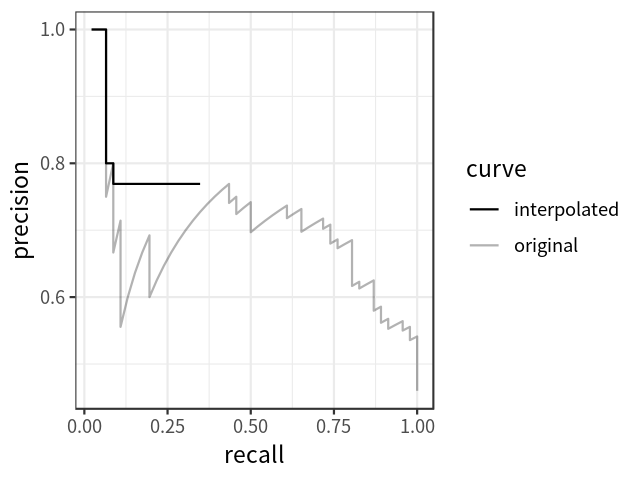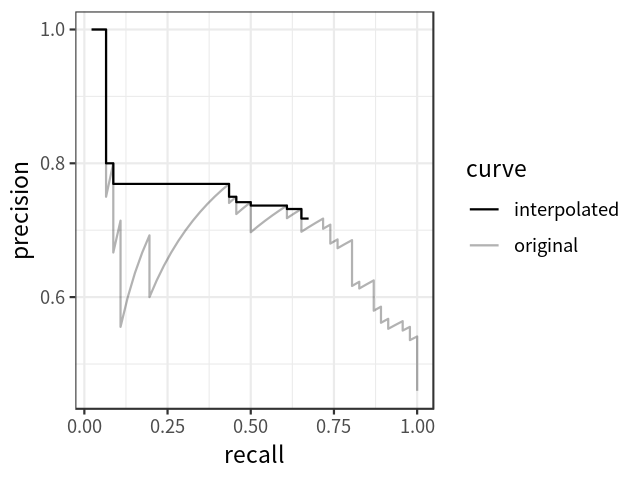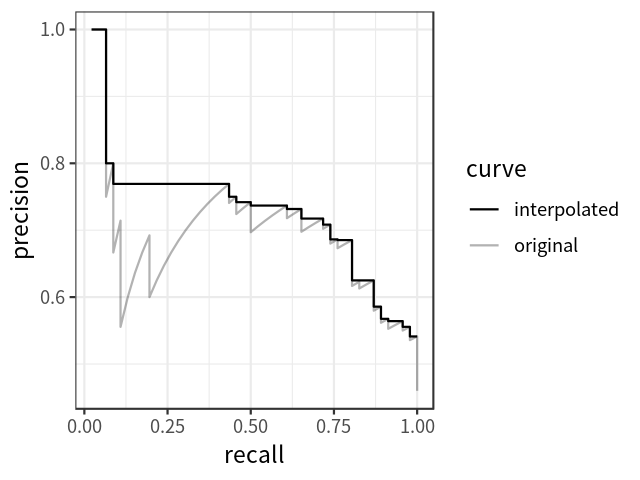
AP can then be defined as the area under the interpolated precision-recall curve, which can be calculated using the following formula:
\[ AP = \sum_{i = 1}^{n - 1} (r_{i + 1} - r_i)p_{interp}(r_{i + 1}) \quad (5) \]
where \(r_1, r_2, ..., r_n\) is the recall levels (in an ascending order) at which the precision is first interpolated.
Mean average precision
The calculation of AP only involves one class. However, in object detection, there are usually \(K > 1\) classes. Mean average precision (mAP) is defined as the mean of AP across all \(K\) classes:
\[ mAP = \frac{\sum_{i = 1}^{K}{AP_i}}{K} \quad (6) \]
Average recall
Like AP, average recall (AR) is also a numerical metric that can be used to compare detector performance. In essence, AR is the recall averaged over all \(IoU \in [0.5, 1.0]\) and can be computed as two times the area under the recall-IoU curve:
\[ AR = 2 \int_{0.5}^{1}recall(o)do \quad (7) \]
where \(o\) is IoU and \(recall(o)\) is the corresponding recall.
It should be noted that for its original purpose (Hosang et al. 2016), the recall-IoU curve does not distinguish among different classes3. However, the COCO challenge makes such distinctions and its AR metric is calculated on a per-class basis, just like AP.
3 This means that the aforementioned pseudocode does not need to include the class contraint to determine true positives which are in turn used to define the recall.
Mean average recall
Mean average recall is defined as the mean of AR across all \(K\) classes:
\[ mAR = \frac{\sum_{i = 1}^{K}{AR_i}}{K} \quad (8) \]
Variations among the metrics
The Pascal VOC challenge’s mAP metric can be seen as a standard metric to evaluate the performance of object detectors; the major metrics adopted by the other two competetions can be seen as variants of the aforementioned metric.
The COCO challenge’s variants
Recall that the Pascal VOC challenge defines the mAP metric using a single IoU threshold of 0.5. However, the COCO challenge defines several mAP metrics using different thresholds, including:
- \(mAP^{IoU=.50:.05:.95}\) which is mAP averaged over 10 IoU thresholds (i.e., 0.50, 0.55, 0.60, …, 0.95) and is the primary challenge metric;
- \(mAP^{IoU=.50}\), which is identical to the Pascal VOC metric;
- \(mAP^{IoU=.75}\), which is a strict metric.
In addition to different IoU thresholds, there are also mAP calculated across different object scales; these variants of mAP are all averaged over 10 IoU thresholds (i.e., 0.50, 0.55, 0.60, …, 0.95):
- \(mAP^{small}\), which is mAP for small objects that covers area less than \(32^2\);
- \(mAP^{medium}\), which is mAP for medium objects that covers area greater than \(32^2\) but less than \(96^2\);
- \(mAP^{large}\), which is mAP for large objects that covers area greater than \(96^2\).
Like mAP, the mAR metric also has many variations. One set of mAR variants vary across different numbers of detections per image:
- \(mAR^{max = 1}\), which is mAR given 1 detection per image;
- \(mAR^{max = 10}\), which is mAR given 10 detections per image;
- \(mAR^{max = 100}\), which is mAR given 100 detections per image.
The other set of mAR variants vary across the size of detected objects:
- \(mAR^{small}\), which is mAR for small objects that covers area less than \(32^2\);
- \(mAR^{medium}\), which is mAR for medium objects that covers area greater than \(32^2\) but less than \(96^2\);
- \(mAR^{large}\), which is mAR for large objects that covers area greater than \(96^2\).
The Open Images challenge’s variants
The Open Images challenge’s object detection metric is a variant of the PASCAL VOC challenge’s mAP metric, which accomodates to three key features of the dataset that affect how true positives and false positives are accounted:
- non-exhaustive image-level labeling;
- semantic hierarchy of classes;
- some ground-truth boxes may contain groups of objects and the exact location of a single object inside the group is unknown.
The official site provides more detailed description on how to deal with these cases.
Implementations
The Tensorflow Object Detection API provides implementations of various metrics.
There is also another opensource project that implements various metrics that respect the competition’s specifications, with an advantage in unifying the input format.