使用回归模型实现时间序列多步预测的几种策略
引言
在参加Kaggle的M5-Accuracy竞赛之前,我一直以为时间序列预测问题就应该使用ARIMA之类的统计学方法解决,而GBDT之类的机器学习算法并不能用于解决此类问题。但在参赛过程中,我发现有许多选手使用后者获得了优异的成绩,这让我感到非常好奇。于是我查阅了相关文献,这才了解到机器学习算法确实能够有效地解决时间序列预测问题(Ben Taieb 等 2012年; Taieb 和 Hyndman 2012年);但我同时也了解到,相比一般的回归问题,使用机器学习算法解决时间序列问题的过程要复杂得多,尤其是当问题涉及多步预测(multi-step forecasting)的时候。
为了提高竞赛成绩1,我根据有关文献的描述,实现了两种将机器学习算法用于多步时间序列预测的策略,包括递归策略(recursive strategy)和直接策略(direct strategy);结果显示,结合这两种策略的机器学习算法确实能够带来更加准确的预测。在这篇文章里,我想对这两种策略的实现方式进行阐述,以便加深自己对它们的理解,也供感兴趣的读者参考。
1 M5-Accuracy竞赛的结果已经公布,我(队伍名:zenggyu)的成绩进入了前3%,获得了银牌。
基本概念、示例数据集及预测问题
在正式介绍两种策略之前,需要先明确一些基本概念;此外,为了使后文的讲解有具体的例子可以参照,本节还将定义一个简单的示例数据集和预测问题。
时间序列预测问题可以被表述成以下一般形式:对含有\(N\)个历史观测值\([y_1, ..., y_N]\)的时间序列,使用其中近\(d\)个历史观测值\([y_{N-d+1}, ..., y_{N}]\),预测未来近\(H\)个时点的观测值\([y_{N+1}, ..., y_{N+H}]\)。在以上表述中,\(1 \leq d \leq N\)被称作嵌入维数;\(H\)被称为预测时间带,且对多步预测而言有\(H > 1\)。下文中,时间序列历史观测值与未来观测值之间的真实函数关系将被记为\(f\),而预测值与观测值之间的误差将被记为\(w\)。
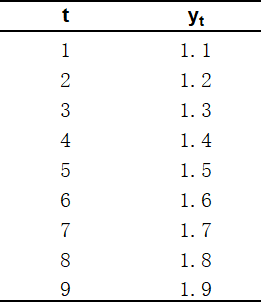
图 1 显示的是一条含有\(N = 9\)个观测值的时间序列;其中,\(t\)代表观测的时间点,\(y_t\)代表对应时间点的观测值。对该序列,我们将使用近3个时间点(\(d = 3\))的观测值,来计算未来4个时间点(\(H = 4\))的预测值,即\(\hat{y}_{10}, \hat{y}_{11}, \hat{y}_{12}, \hat{y}_{13}\)。
递归策略
在使用递归策略进行时间序列的多步预测时,首先要按式(1)所示函数关系训练出1个单步预测模型:
\[ (1) \quad y_{t+1} = f(y_{t-d+1}, ..., y_{t}) + w \]
为了训练这样的模型,我们需要使用滑窗方法对原始时间序列进行处理,得到一个包含上述输入输出关系的数据集。以 图 1 中的时间序列为例,一个满足要求的数据集如 图 2 蓝色部分所示2。在得到该数据集之后,即可将\(y_{t+1}\)作为因变量、\((y_{t-2}, y_{t-1}, y_{t})\)作为自变量训练回归模型;其训练方法与一般回归模型的训练方法相同,此处不再赘述。
2 经滑窗处理后,数据集中会出现缺失值(即 图 2 灰色部分符号“-”代表的值);由于许多机器学习算法不支持缺失值作为输入,因此一般而言式(1)中的\(t\)需满足\(t \in \{d, ..., N-1\}\)。
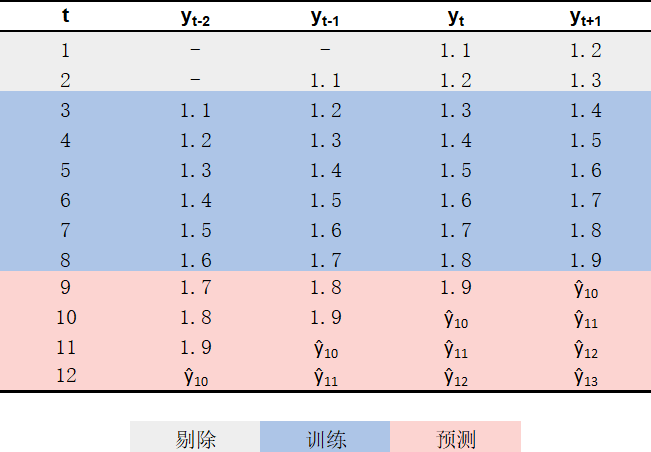
在根据以上方法得到单步预测模型\(\hat{f}\)之后,我们就可以开始对时间序列进行多步预测了。就本文的例子而言,模型需要使用 图 2 红色部分所示的\((y_{t-2}, y_{t-1}, y_{t})\)作为输入,并输出\(y_{t+1}\)的预测值。与一般的回归问题的预测过程不一样,此时模型的输入并不完整,其中存在尚未确定、待预测的值,需要以式(2)所示的递归的方式分步完成预测过程3;具体步骤如下:
3 值得注意的是,当\(h = 1\)时,模型的输入全部都是观测值;当\(h \in \{2, ..., d\}\)时,输入同时含有观测值和预测值;而当\(h \in \{d+1, ..., H\}\)时,输入全部都是预测值。
- 以\((y_{7}, y_{8}, y_{9})\)作为模型输入,得到\(\hat{y}_{10}\);
- 以\((y_{8}, y_{9}, \hat{y}_{10})\)作为模型输入,得到\(\hat{y}_{11}\);
- 以\((y_{9}, \hat{y}_{10}, \hat{y}_{11})\)作为模型输入,得到\(\hat{y}_{12}\);
- 以\((\hat{y}_{10}, \hat{y}_{11}, \hat{y}_{12})\)作为模型输入,得到\(\hat{y}_{13}\)。
\[ (2) \quad \hat{y}_{N+h} = \begin{cases} \begin{align} &\hat{f}(y_{N-d+1}, ..., y_N) &h = 1 \\ &\hat{f}(y_{N-d+h}, ..., y_N, \hat{y}_{N+1}, ..., \hat{y}_{N+h-1}) &h \in \{2, ..., d\} \\ &\hat{f}(\hat{y}_{N+h-d}, ..., \hat{y}_{N+h-1}) &h \in \{d+1, ..., H\} \end{align} \end{cases} \]
直接策略
在使用直接策略进行时间序列的多步预测时,需要按式(3)所示函数关系训练出\(H\)个独立的预测模型,分别用于预测未来不同时间点的观测值。
\[ (3) \quad y_{t+h} = f_{h}(y_{t-d+1}, ..., y_{t}) + w, \quad h \in \{1, ..., H\} \]
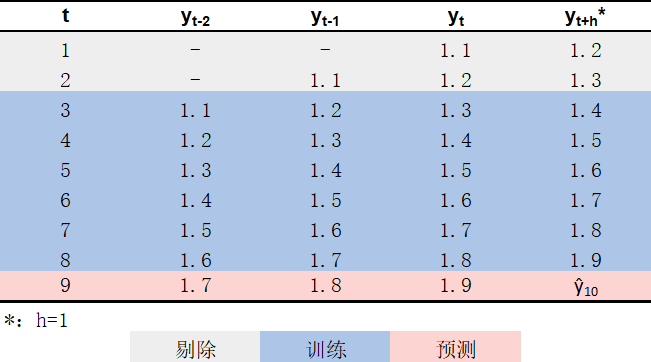
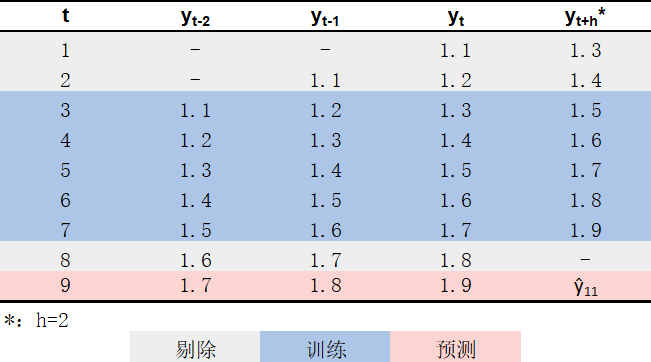
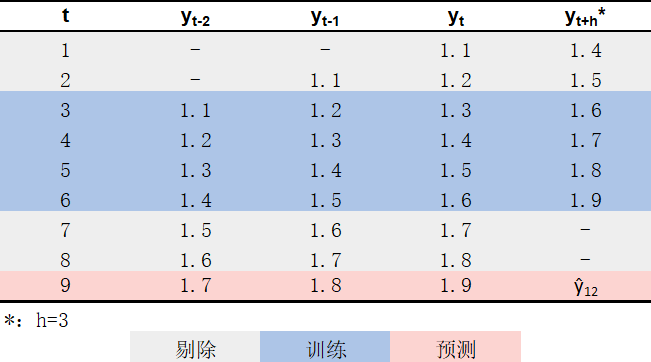
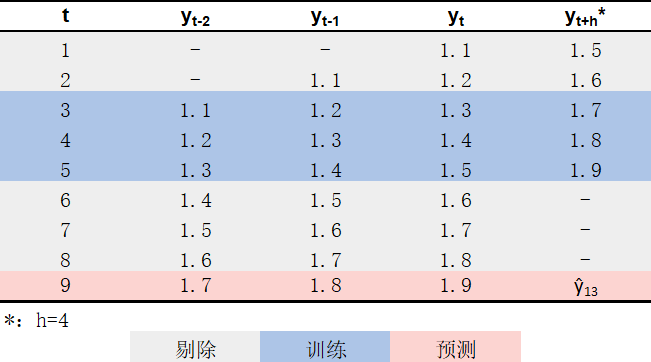
为了训练上述模型,我们需要使用滑窗方法对原始时间序列进行处理,分别得到\(H\)个包含对应输入输出关系的数据集。回到本文提出的例子,满足要求的\(H = 4\)个数据集分别如 图 3 、 图 4 、 图 5 和 图 6 蓝色部分所示4。在得到这些数据集之后,即可将\(y_{t+h}\)作为因变量、\((y_{t-2}, y_{t-1}, y_{t})\)作为自变量,使用各数据集分别训练1个回归模型\(\hat{f}_{h}\);具体而言:
- 使用表3蓝色部分所示数据进行训练,得到模型\(\hat{f}_1\);
- 使用表4蓝色部分所示数据进行训练,得到模型\(\hat{f}_2\);
- 使用表5蓝色部分所示数据进行训练,得到模型\(\hat{f}_3\);
- 使用表6蓝色部分所示数据进行训练,得到模型\(\hat{f}_4\)。
在通过上述方法得到各个模型之后,将\((y_{N-d+1}, ..., y_{N})\),分别输入各个模型,即可得到对应时间点的预测值;该过程如式(4)所示(本例中\(N = 9, d = 3, H = 4\))。
\[ (4) \quad \hat{y}_{N+h} = \hat{f}_h(y_{N-d+1}, ..., y_{N}), \quad h \in \{1, ..., H\} \]
如果严格按照直接策略的要求,一个模型只应被用于预测一个时间点的值;但细心的读者可能会发现,有些模型其实可以同时被用于预测多个时间点的值。例如,\(\hat{f}_4\)可以被用于预测\(y_{10}, y_{11}, y_{12}, y_{13}\)(不过正如 图 6 所示,该模型所能使用的训练数据较少、且无法利用到最接近待预测时点的信息,因此准确度可能会较差),这意味着所需要拟合的模型个数可以小于预测时间窗口所含的时间点个数。在处理实际问题时,如果预测时间窗口较长,适当利用该规律可以在不明显降低预测准确性的情况下大大减少所需拟合的模型数量。例如,假设要预测商品在未来28天里每天的销量,如果严格遵循直接策略,需要训练28个模型(\(\hat{f}_{1}, ..., \hat{f}_{28}\))分别用于预测各天的销量;但若稍微放宽直接策略的要求,可以只训练4个模型(\(\hat{f}_{7}, \hat{f}_{14}, \hat{f}_{21}, \hat{f}_{28}\)),分别用于预测第一、二、三、四周里各天的销量5。
5 在Kaggle M5-Accuracy竞赛中排名第四的解决方案用的就是这种方法。
小结
本文主要介绍了两种常见的将机器学习算法应用于时间序列预测的策略,即递归策略和直接策略。本文的主要目的在于介绍这两种策略的实现方式;但对这两种策略的适用情形以及优劣性的比较不在本文希望探讨的范围内,感兴趣的读者可以参阅(Ben Taieb 等 2012年; Taieb 和 Hyndman 2012年);除了本文所介绍的策略之外,这两篇文献还研究比较了其他几种预测策略。
在本文的最后,我还想再简单地谈谈两点与时间序列预测相关的内容。
关于时间序列模型的特征工程。为了简化描述,本文只使用了时间序列的原始值作为模型的输入特征;在处理实际问题时,往往还会用到原始值的滑窗统计量(例如近若干个时点观测值的均值、标准差等),甚至还会用到一些外部特征(即并非由要预测的时间序列本身的观测值构建的特征)。但无论要构建何种特征,均要切记所构建的特征必须是能够在预测阶段获取的特征,否则会造成数据泄露(data leakage)及模型的过拟合。
关于同时对多条时间序列进行建模和预测。与本文所提出的预测问题不同,现实中的时间序列预测问题往往涉及多条时间序列;例如,M5竞赛就要求对三万多条时间序列预进行测。面对这种问题,传统的统计学方法要求对每条时间序列分别建立一个模型;但机器学习模型可以同时对多条时间序列进行拟合和预测。简单地说,其实现方法就是在数据集中加上一个能够标识各时间序列的特征作为模型的输入;当所涉及的时间序列数量较多时,对该特征使用目标编码,可以获得更好的效果。