数据库基本范式的实现条件及方法
本文介绍了数据库几个基本范式的实现条件;并且,还通过一个具体的例子讲解了对一个非规范化表进行改造、使之满足各个基本范式的过程。
引言
数据库规范化(normalization),又称正规化、标准化,是数据库设计中对表结构进行调整、使之满足关系表的格式要求并减少数据冗余的过程。规范化的主要意义在于通过避免更新异常(update anomaly) 1 以提高数据一致性,同时也有利于数据模型的扩展。
1 可以进一步分为插入异常(insertion anomaly)、删除异常(deletion anomaly)和修改异常(modification anomaly)。
2 1NF是形成关系表(relation)的充要条件,即满足1NF的表都是关系表,且关系表均满足1NF。另外,只要满足1NF,表就可以被视为已经得到规范化(normalised)。
表的规范程度从低到高可以分为:非规范化形式(UNF);第一范式(1NF) 2 ;第二范式(2NF);第三范式(3NF);主键范式(EKNF);Boyce-Codd范式(BCNF);第四范式(4NF);关键元组范式(ETNF);第五范式(5NF);域键范式(DKNF);第六范式(6NF) (Date 2019年) 。满足较高范式的表也必定满足较低的范式,例如:满足3NF的表也必定满足2NF和1NF。
虽然数据表的范式越高,数据一致性就越容易得到保证,但其代价是表数量以及查询复杂度的增加。因此,实际应用中并不应该盲目地追求高范式;多数情况下,只要达到3NF即可 (Connolly 和 Beg 2015年; Carlos Coronel 和 Steven Morris 2018年; Date 2019年) ;更高等级的范式通常只具备理论研究价值。
本文的主要目的在于介绍主要范式的实现条件,以及对低范式表进行规范化、从而使之达到更高范式的方法。为了使内容更具参考价值和可操作性,本文将引入一个具体的例子进行讲解;考虑到实用性,本文对相关内容的介绍将止于3NF、而不会涉及更高等级的范式。另外,本文将假设读者已经对键(key)和函数依赖(functional dependency)等数据库规范化的理论基础概念有所了解 3 。
3 具体包括:候选键(candidate key)、主键(primary key)、复合键(composite key)、部分依赖(partial dependency)和传递依赖(transitive dependency)等
一个UNF表实例
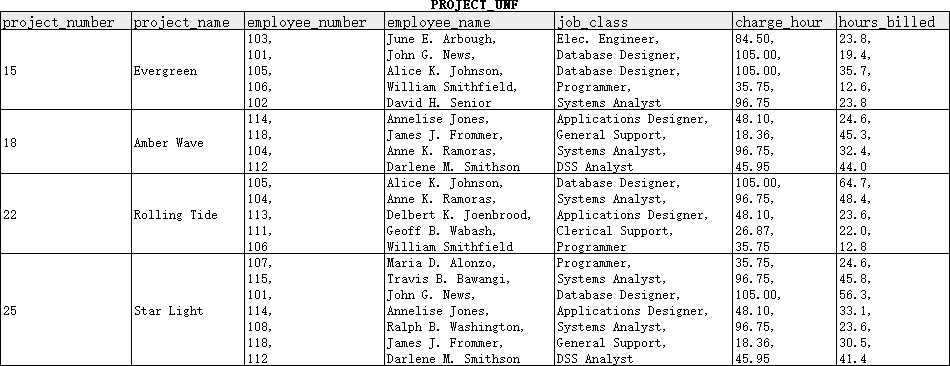
图 1 所示的PROJECT_UNF表记录了某家公司的项目数据(Carlos Coronel 和 Steven Morris 2018年),其中:每行代表一个项目;每个项目都对应一个项目编号(project_number)、项目名称(project_name),以及若干个参与该项目的员工;每个员工都对应一个员工编号(employee_number)、员工姓名(employee_name)和职位(job_class);每个职位都对应一个时薪标准(charge_hour);对参与各个项目的不同员工,该表还记录了相应的工作时长(hours_billed)。值得注意的是,由于一条项目记录对应了多条员工、时薪及工作时长记录,该表中的某些列(如employee_number、employee_name等等)下的单元格含有多个取值,且各取值之间以逗号间隔。
1NF的实现条件及方法
要实现1NF,一张表必须满足以下所有条件:
- 表中不含有重复组(repeating group),即各行/列交叉处的单元格不应含有多个取值 4 ;
- 表中确定了主键。
4 单元格内是否含有需要拆分的多个取值是个容易出现争议的问题,必须结合数据的具体用途决定。
回顾PROJECT_UNF,不难发现employee_number、employee_name、job_class、charge_hour和hours_billed等列下的单元格含有多个取值,所以该表并不符合1NF的第1个条件。要使之达到1NF,需要对其进行以下改造:
- 去除重复组。
employee_number等列下的单元格含有多个取值,需要将其拆分,使得每个单元格仅包含一个取值。拆分有两种方式5:第一种方式是将一个单元格拆分成多行,其结果如表PROJECT_1NFa所示( 图 2 上);第二种方式是将一个单元格拆分成多列,其结果如表PROJECT_1NFb所示( 图 2 下)。 - 确定主键。如果选择上述第一种拆分方式,可以发现
project_number和employee_number这两个字段的取值组合能够确定每一行其他字段的取值,因此它们可以作为表的主键;另一方面,选择上述第二种方式拆分单元格后得到的结果表可以使用project_number作为主键。
5 根据 Silberschatz 等 (2019年) 提出的建议,在对多值属性(multivalued attribute)进行拆分时,应该选用第一种方式(将一个单元格拆分成多行);在对复合属性(composite attribute)进行拆分时,应该选用第二种方式(将一个单元格拆分成多列)。在本例中,需要拆分的属性均为多值属性,因此最好选择前者,以避免后面将提到的问题。这里把两种方式都拿出来讲只是为了内容的完整性。
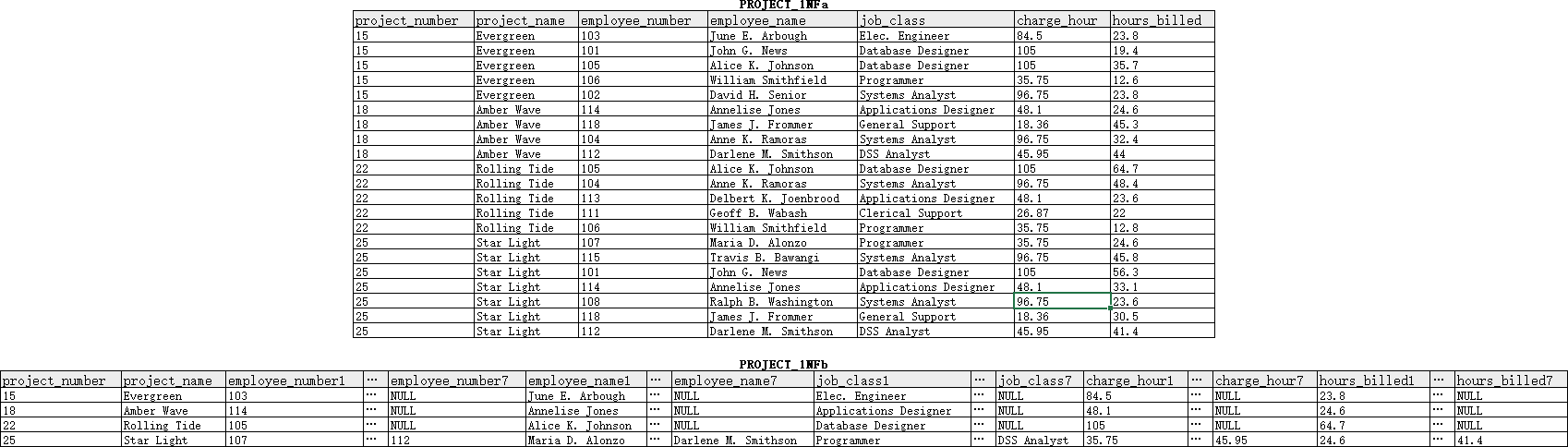
尽管从前述定义角度看,表PROJECT_1NFa和表PROJECT_1NFb都满足1NF,但在实际应用中通常还是会倾向于采用前者,这是因为后者具有以下几项缺点:1. 需要对原单元格进行拆分后得到的列的个数做出明确限定,显得不够灵活;2. 容易引入空值,造成处理上的不便;3. 当拆分出的列数较多时,不便于进行某些查询(例如每个项目的参与人数);4. 不便于被进一步优化至3NF。考虑到这些因素,下文将仅以表PROJECT_1NFa为例进行进一步优化。
2NF的实现条件及方法
要实现2NF,一张表必须满足以下所有条件:
- 已实现1NF;
- 表中不存在部分依赖。
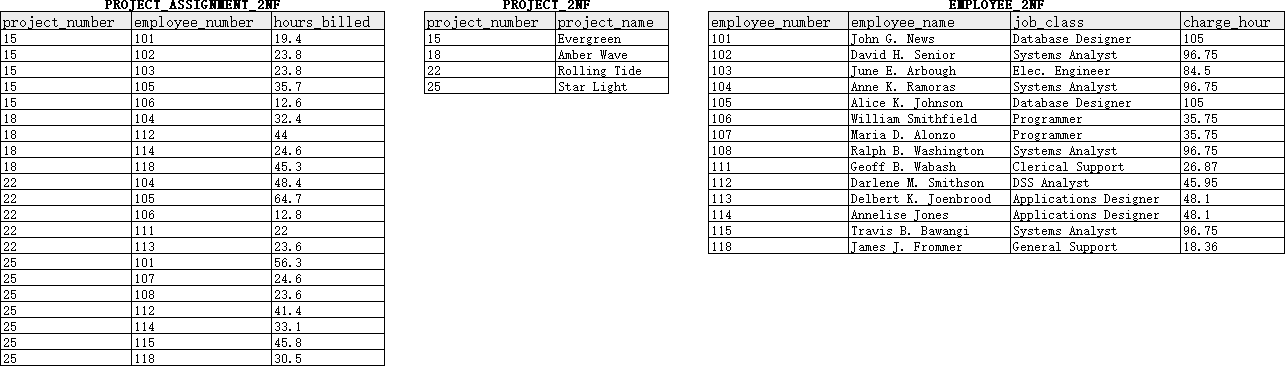
我们已经知道,project_number和employee_number组成了表PROJECT_1NFa的一个候选键(该候选键同时也是主键);然而,回顾前文对例表内容描述中所隐含的业务规则,我们会发现表PROJECT_1NFa中的project_name仅依赖于project_number,而employee_name、job_class、charge_hour则仅依赖于employee_number。这说明该表中存在部分依赖。如果要实现2NF,需要对PROJECT_1NFa进行以下改造:
- 为每一个涉及到部分依赖的主键属性(primary-key attribute)构建一个新的表,并以该属性作为新表的主键。由于
project_number和employee_number均各自涉及到部分依赖,因此需要新增两个表PROJECT_2NF和EMPLOYEE_2NF,并分别以project_number和employee_number作为它们的主键。 - 将依赖于上述主键属性的列移动到新的表中。由于
project_name依赖于project_number,因此需要将project_name从PROJECT_1NFa移动到PROJECT_2NF;同理,还需要把employee_name、job_class和charge_hour从PROJECT_1NFa移动到EMPLOYEE_2NF中。在进行移动之后,表PROJECT_1NFa只剩下project_number、employee_number和hours_billed等三个字段,并满足2NF,我们可以将其重命名为PROJECT_ASSIGNMENT_2NF。
经上述步骤,我们获得了PROJECT_ASSIGNMENT_2NF、PROJECT_2NF和EMPLOYEE_2NF三个表(见 图 3 ),并且它们均实现了2NF。
3NF的实现条件及方法
要实现3NF,一张表必须满足以下所有条件:
- 满足2NF;
- 表中不存在传递依赖。
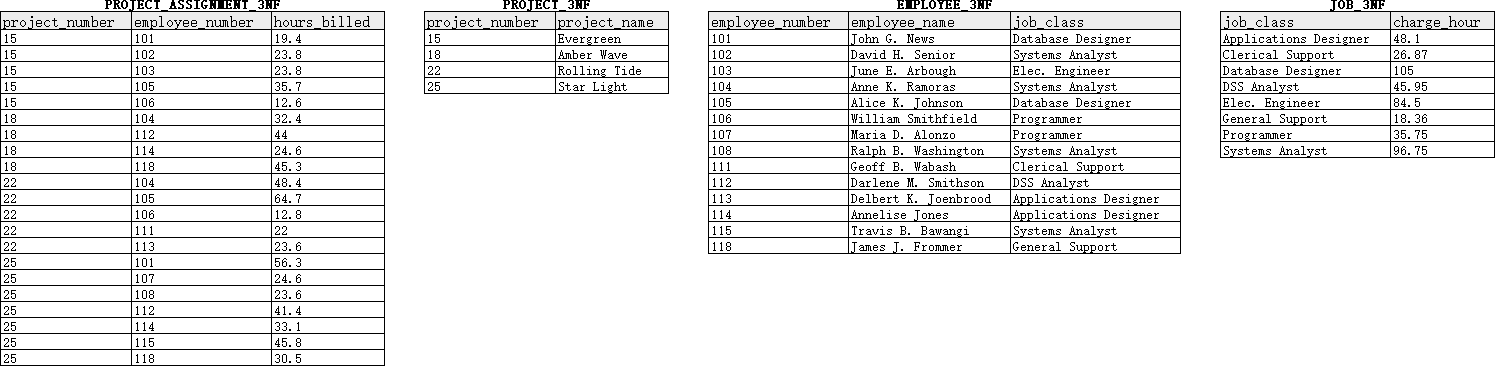
观察EMPLOYEE_2NF,我们会发现charge_hour实际上并不直接依赖于该表的主键employee_number,而是直接依赖于非主键属性job_class(而job_class则直接依赖于主键employee_number);这说明该表中存在传递依赖。如果要实现3NF,需要对EMPLOYEE_2NF进行以下改造:
- 为传递依赖中起决定因素作用的每个非主键属性构建一个新的表,并以该属性作为新表的主键。在表
EMPLOYEE_2NF中,由于charge_hour直接依赖于非主键属性job_class,因此可以构建一个新表JOB_3NF,并且以job_class作为该表的主键。 - 将依赖于上述非主键属性的列移动到新的表中。在此例中,需要将
charge_hour移动到JOB_3NF。在进行移动之后,EMPLOYEE_2NF只剩下employee_number、employee_name和job_class字段,并且满足3NF,我们可以将其重命名为EMPLOYEE_3NF。
另一方面,由于PROJECT_2NF和PROJECT_ASSIGNMENT_2NF中的所有非主键属性(non-primary-key attribute)都直接且完全依赖于对应表的主键、不存在传递依赖,所以这两个表事实上已经满足3NF、无需进一步改造;为了反映这一事实,我们可以直接将它们重新命名为PROJECT_3NF和PROJECT_ASSIGNMENT_3NF。
经上述步骤,我们获得了PROJECT_ASSIGNMENT_3NF、PROJECT_3NF、EMPLOYEE_3NF和JOB_3NF四个表(见 图 4 ),并且它们均实现了3NF。
小结
本文主要从实用角度出发,介绍了数据库基本范式的实现条件和方法,以便能够在实际工作中直接应用。另外,本文还在开头简单提及了数据库规范化的意义(如减少数据冗余、提高数据一致性、有利于数据模型的扩展等),但并未就此做出更进一步的介绍;对该主题感兴趣的读者可以参考文末列出的相关文献。
最后,这里再对1NF、2NF和3NF进行一些补充说明:
- 尽管重复组的存在与否是判断一张表是否满足1NF的重要条件,但人们对“重复组”的定义却存在分歧(Date 2019年),导致1NF的定义也变得模糊。根据 Connolly 和 Beg (2015年) 给出的定义6,本文所示的表
PROJECT_1NFb并不能被认为是满足1NF的;然而,根据 Date (2019年) 的看法7,该表虽然存在不好的设计,却并未违反1NF的条件。 - 本文所使用的例表中,只含有一个候选键,且该候选键就是主键;然而,在现实中,一个表可能含有多个候选键,而部分依赖和传递依赖可能发生在任意候选键上。因此,在判断一个表格是否满足2NF或3NF时,需要针对每个候选键判断是否存在部分依赖和传递依赖;并且,在进行规范化时,也需分别针对各个候选键上的部分依赖和传递依赖进行处理。
6 “A repeating group is an attribute, or group of attributes, within a table that occurs with multiple values for a single occurrence of the nominated key attribute(s) for that table.”
7 “…, a repeating group is not ‘when you repeat the same basic attribute over and over again.’”